Team logo:
Xue Feng (Professor)
Li Shujie (Lecturer)
Research achievements:
1.Visual Multimedia Analysis:
This research direction involves the integration of theoretical study with practical engineering applications. Key research topics include target detection, defect detection, and lip reading, addressing typical problems in computer vision. Research outcomes in this area have been published in high-profile conferences and journals such as TMM, TCSVT, and TOMM. Developed systems have been applied within multiple enterprises.
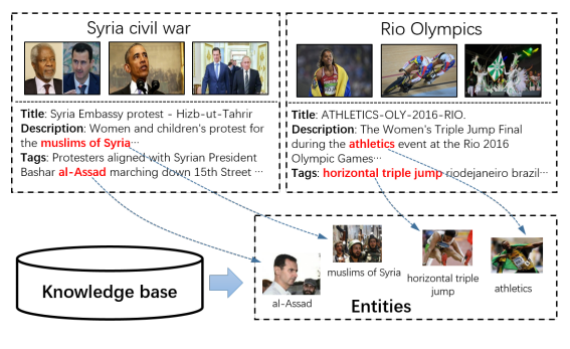
Figure 1. Topic model of knowledge embedding for multimodal social event analysis
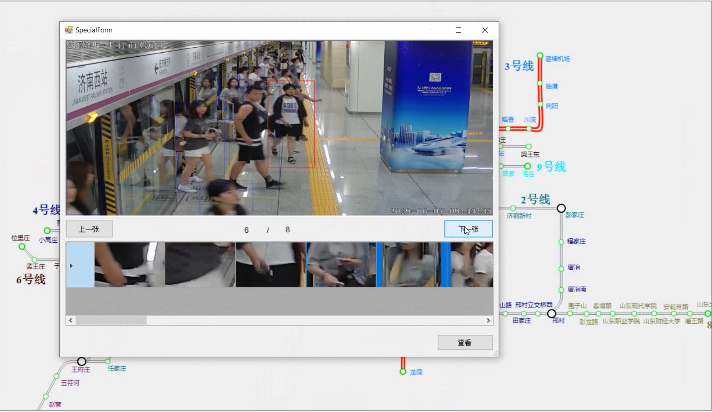
Figure 2. Subway COVID-19 close contact tracking system based on pedestrian re-identification
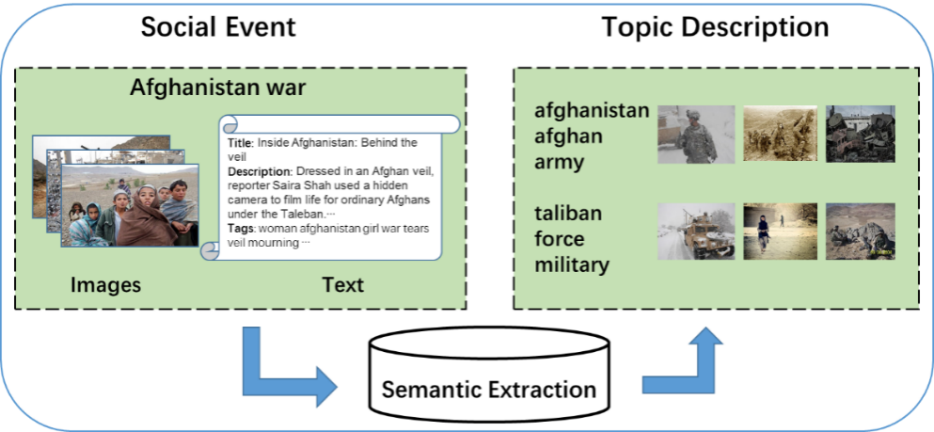
Figure 3. Semantic-based multimodal supervised topic model for event classification

Figure 4. Hard hat detection algorithm
2.Intelligent Recommendation Systems:
The primary theoretical focus of Professor Xue's team is on intelligent recommendation systems. Research within this domain includes multimedia recommendation and recommendation systems based on causal assumptions. Notable achievements in this field have been published in high-impact international journals and conferences such as TOIS, TCSS, and SIGIR. The proposed DeepICF personalized recommendation algorithm, published in the top-tier journal ACM TOIS in 2019, has garnered significant attention with 287 citations on Google Scholar. It also secured the second position in the 2018 Mobile Knowledge Sharing Platform Recommendation Algorithm Online Evaluation Competition (co-organized by Zhihu Company and Tsinghua University).
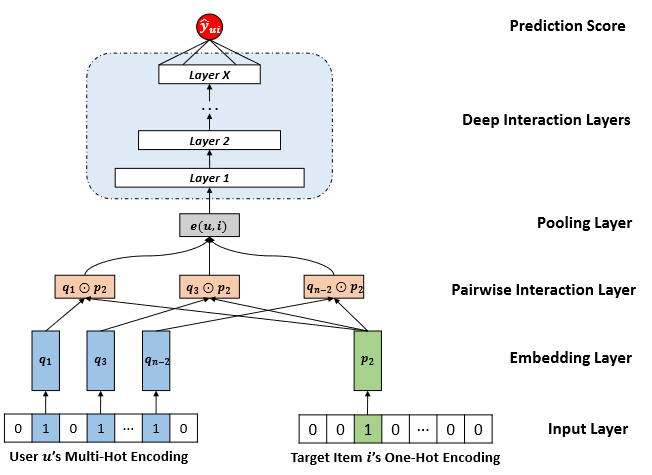
Figure 5. Our proposed neural network architecture of Deep Item-based Collaborative Filtering

Figure 6.Framework of our proposed Multimodal Entity Graph Collaborative Filtering

Figure 7. Second place in the "Zhihu Online Recommendation Competition" based on the DeepICF algorithm (only one first prize winner)

Figure 8 Second Prize for "CCIR2018 Knowledge Sharing Platform Content Recommendation in Mobile Environment"
3. Human pose estimation
Human pose estimation with deep learning involves estimating the configuration of human body parts from input images or videos, which has been extensively studied in computer vision literature. We engaged in this research direction since 2017. Achievements in this field have been published in Computers & Graphics, Journal of Computer-Aided Design & Computer Graphics. The feature of our work is that we can directly map the real people in the video into animated characters. Our work can be used for somatosensory games, film production, game production, etc.

Figure 9. Real people in the video is directly mapped into animated characters.
Representative Academic Papers:
[1] Feng Xue*, Xiangnan He, Xiang Wang, Jiandong Xu, Kai Liu, and Richang Hong. 2019. Deep Item-based Collaborative Filtering for Top-N Recommendation, ACM Transactions on Information Systems, 2019, 37(3): 1-25. (CCF-A, 287 Google citations, highly cited paper)
[2] Liu, Kang, Feng Xue*, Dan Guo, Le Wu, Shujie Li and Richang Hong. 2023. MEGCF: Multimodal Entity Graph Collaborative Filtering for Personalized Recommendation. ACM Transactions on Information Systems. ACM Transactions on Information Systems 41, 2 (2023), 1-27. (CCF A)
[3] Shuaiyang Li, Dan Guo, Kang Liu, Richang Hong, and Feng Xue*. 2023. Multimodal Counterfactual Learning Network for Multimedia-based Recommendation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2023, 1-10. July 23–27, 2023, Taipei, Taiwan of China. (SIGIR, CCF A)
[4] Feng Xue, Tian Yang, Kang Liu, Zikun Hong, Mingwei Cao, Dan Guo and Richang Hong. 2023. LCSNet: End-to-End Lipreading with Channel-Aware Feature Selection. ACM Transactions on Multimedia Computing, Communications, and Applications. 19, 1s 2023, 1-21. (CCF B)
[5] Liu, Kang, Feng Xue*, Dan Guo, Peijie Sun, Shengsheng Qian and Richang Hong. 2023. Multimodal Graph Contrastive Learning for Multimedia-Based Recommendation. IEEE Transactions on Multimedia. 2023, 1-13. (SCI 1,CCF B,TOP)
[6] Feng Xue,Richang Hong*,Xiangnan He,Jianwei Wang,Shengsheng Qian,Changsheng Xu. Knowledge-Based Topic Model for Multi-Modal Social Event Analysis. IEEE Transactions on Multimedia. 22, 8 2019, 2098-2110. (SCI 1,CCF B,TOP)
[7] Feng Xue, Yu Li, Deyin Liu, Yincen Xie, Lin Wu, Richang Hong. 2023. LipFormer: Learning to Lipread Unseen Speakers Based on Visual-Landmark Transformers. IEEE Transactions on Circuits and Systems for Video Technology, 9(2023), 4507 - 4517 (CCF B,TOP)
[8] Naiyang Miao, Feng Xue*, and Richang Hong; Multi-Modal Semantics-Based Supervised Latent Dirichlet Allocation for Event Classication, in IEEE MultiMedia, vol., no. 01, pp. 1-1, 5555.doi: 10.1109/MMUL.2021.3077915. (ChinaMM2020, Best Paper Award)
[9] Shujie Li; Lei Wang; Wei Jia; Yang Zhao; Liping Zheng ; An iterative solution for improving the generalization ability of unsupervised skeleton motion retargeting, Computers & Graphics, 2022, 2022(104): 129-139
[10] Shujie Li ; Yang Zhou; Haishen Zhu; Wenjun Xie; Yang Zhao; Xiaoping Liu. Bidirectional Recurrent Autoencoder for 3D Skeleton Motion Data Refinement, Computers & Graphics, 2019(81), 92–103

 TOP
TOP